INSERT INTO 테이블명(칼럼명1, 칼럼명2,..) VALUES(v1, v2,...)
1.2 예제
실습용 테이블 생성
CREATE TABLE LINK (
ID SERIAL PRIMARY KEY
, URL VARCHAR (255) NOT NULL
, NAME VARCHAR (255) NOT NULL
, DESCRIPTION VARCHAR (255)
, REL VARCHAR (50)
);
SELECT * FROM LINK;
id
url
name
description
rel
1개의 데이터 행 추가
INSERT INTO LINK (URL, NAME)
VALUES ('http://naver.com','Naver');
COMMIT;
SELECT * FROM LINK;
id
url
name
description
rel
0
1
http://naver.com
Naver
None
None
작은따옴표를 데이터로 입력
INSERT INTO LINK(URL, NAME)
VALUES ('''http://naver.com''', '''Naver''');
COMMIT;
SELECT * FROM LINK;
id
url
name
description
rel
0
1
http://naver.com
Naver
None
None
1
2
'http://naver.com'
'Naver'
None
None
여러 개의 데이터 행 추가
INSERT INTO LINK(URL, NAME)
VALUES ('http://www.google.com','Google')
, ('http://www.yahoo.com' ,'Yahoo')
, ('http://www.bing.com' ,'Bing')
;
COMMIT;
SELECT * FROM LINK;
id
url
name
description
rel
0
1
http://naver.com
Naver
None
None
1
2
'http://naver.com'
'Naver'
None
None
2
3
http://www.google.com
Google
None
None
3
4
http://www.yahoo.com
Yahoo
None
None
4
5
http://www.bing.com
Bing
None
None
다른 테이블을 이용해 스키마만 있는 빈 껍데기 테이블 생성
CREATE TABLE LINK_TMP AS
SELECT * FROM LINK WHERE 0=1;
COMMIT
SELECT * FROM LINK_TMP
id
url
name
description
rel
다른 테이블로부터 SELECT 하여 데이터 삽입
INSERT INTO LINK_TMP
SELECT * FROM LINK;
COMMIT;
SELECT * FROM LINK_TMP
id
url
name
description
rel
0
1
http://naver.com
Naver
None
None
1
2
'http://naver.com'
'Naver'
None
None
2
3
http://www.google.com
Google
None
None
3
4
http://www.yahoo.com
Yahoo
None
None
4
5
http://www.bing.com
Bing
None
None
2. UPDATE문
테이블 안에 데이터를 편집할 때 사용하는 명령어
2.1 문법
UPDATE 테이블명 SET 컬럼명 = 값 WHERE 조건
2.2 예제
name 이 'Naver'인 데이터의 description을 name 컬럼값으로 수정
UPDATE LINK SET DESCRIPTION = NAME
WHERE NAME = 'Naver'
COMMIT;
SELECT * FROM LINK
id
url
name
description
rel
0
2
'http://naver.com'
'Naver'
None
None
1
3
http://www.google.com
Google
None
None
2
4
http://www.yahoo.com
Yahoo
None
None
3
5
http://www.bing.com
Bing
None
None
4
1
http://naver.com
Naver
Naver
None
3. UPDATE JOIN 문
다른 테이블의 값을 참조하여 한 테이블의 값을 편집할 때 사용하는 명령어
3.1 문법
UPDATE 테이블1 A SET A.컬럼 = 값 FROM 테이블2 B WHERE A.컬럼 = B.컬럼
# 1. id값을 직접 전달
QgsProject.instance().removeMapLayer('ifaceLink_32ac8313_af37_4c95_a181_274d20739ec1')
# 2. layer명.id() 를 인자로 전달
QgsProject.instance().removeMapLayer(node.id()))
# 3. 다시 레이어 조회
QgsProject.instance().mapLayers()
theFeatures = theLayer.dataProvider() # Feature를 다루는 class 할당
theFeatures.addAttributes([QgsField("ID", QVariant.Int),QgsField("Name", QVariant.String)])
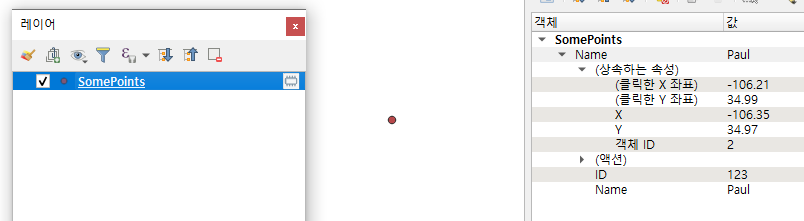
레이어에 feature 추가 하기
p=QgsFeature() # 빈 feature 생성
point = QgsPointXY(-106.3463, 34.9685) # 임시 Geometry 클래스 생성
p.setGeometry(QgsGeometry.fromPointXY(point)) # 임시 Geometry를 p feature에 set
p.setAttributes([123,"Paul"]) # 속성 정보를 p feature에 set
theFeatures.addFeatures([p]) # Features class에 p를 add
theLayer.updateExtents() # 범위를 업데이트
theLayer.updateFields() # 속성정보를 업데이트
QgsProject.instance().addMapLayers([theLayer]) # 레이어 로딩
# 1. postgresql 서버에 연결하여 polygon 데이터 조회하기
import psycopg2
connection = psycopg2.connect(database='geospatial', user='postgres', password='qkrtkddus!1')
cursor = connection.cursor()
cursor.execute("select *, ST_AsTexT(geom) from tl_scco_ctprvn")
c = cursor.fetchall()
# 2. QGIS 레이어 및 Feature 생성(속성 필드 추가)
sigungu = QgsVectorLayer('Polygon','Sigungu','memory')
sigunguFeatures = sigungu.dataProvider()
sigunguFeatures.addAttributes([QgsField("ID", QVariant.Int), QgsField("Name",QVariant.String)])
# 3. QGIS 레이어에 postgresql 에서 조회해온 데이터 삽입하기
for poly in c:
g=QgsGeometry.fromWkt(poly[5]) # geometry 저장
p=QgsFeature() # 빈 feature 생성
p.setGeometry(g) # feature 에 geometry setting
p.setAttributes([poly[1], str(poly[3])]) # feature 에 속성 setting
sigunguFeatures.addFeatures([p]) # features 변수에 feature 추가
sigungu.updateExtents() # 범위를 업데이트
sigungu.updateFields() # 속성정보를 업데이트
QgsProject.instance().addMapLayers([sigungu]) # 레이어 로딩
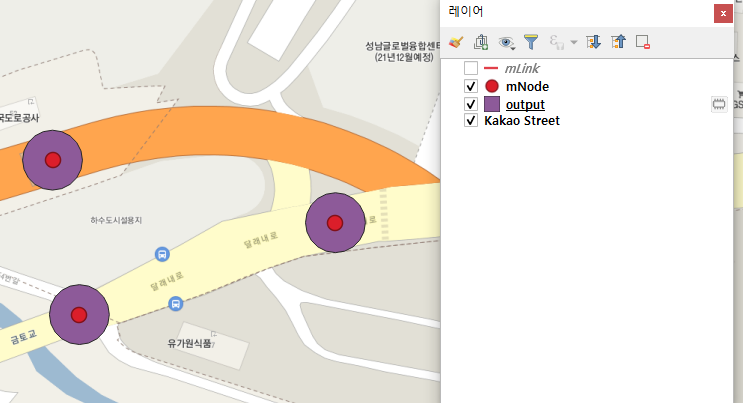
7. Feature 추가, 편집, 삭제, 조회
앞선 2. 레이어 로딩하기에서 로딩한 Node 데이터로 예제 진행
레어어에 가능한 작업 리스트 확인
node.dataProvider().capabilitiesString()
'객체 추가, 객체 삭제, 속성 값 변경, 속성 추가, 속성 삭제, 속성 이름 바꾸기, 공간 인덱스 생성, 속성 인덱스 생성, ID로 빠른 객체 접근, 도형 변경'
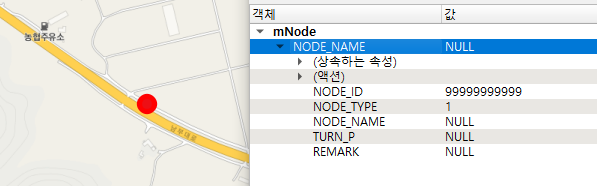
7.1 Feature 추가
새로운 Node 1개 추가
feat = QgsFeature(node.fields())
feat.setAttribute('NODE_ID', 99999999999)
feat.setAttribute('NODE_TYPE', 1)
# 또는 위의 코드를 아래와 같이 한줄로 표현 가능
# feat.setAttributes([999999999999, 1 , ...속성값들])
feat.setGeometry(QgsGeometry.fromPointXY(QgsPointXY(221689.09,462751.59)))
node.dataProvider().addFeatures([feat])
추가 전
추가 후
7.2 Feature 삭제
차선이 1개인 링크 삭제
deleteList = []
for x in link.getFeatures():
if x["LANES"] == 1:
deleteList.append(x.id())
link.dataProvider().deleteFeatures(deleteList)
삭제 전
삭제 후
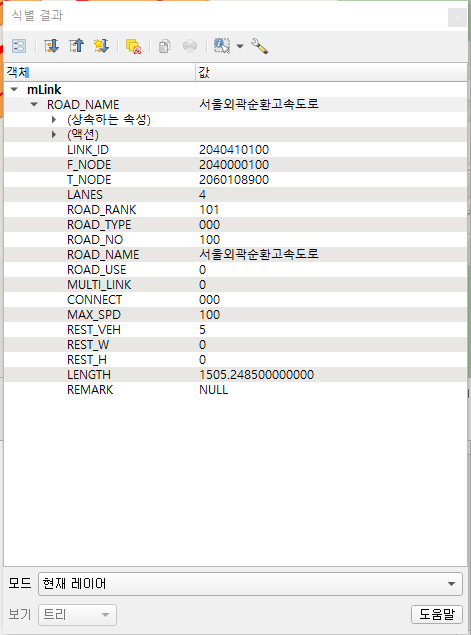
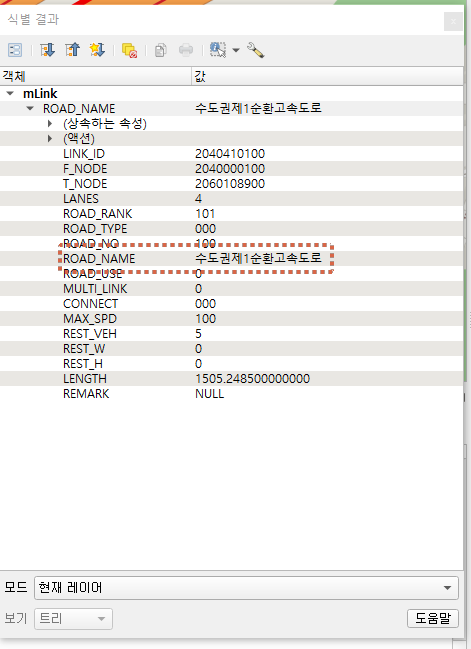
7.3 Feature 편집
'서울외곽순환고속도로' 링크를 '수도권제1순환고속도로'로 명칭 변경
for x in link.getFeatures():
if x['ROAD_NAME'] == '서울외곽순환고속도로':
link.dataProvider().changeAttributeValues({x.id():{7:'수도권제1순환고속도로'}})
변경 전
변경 후
7.4 Feature 선택(수식 이용)
도로번호가 1이면서 도로명이 '경부고속도로인 링크 선택하기
link.selectByExpression("ROAD_NO=1 and ROAD_NAME='경부고속도로'")
변경 전
변경 후
8. Toolbox
8.1 Toolbox 사용하기
사용 가능한 Toolbox 기능 리스트 확인하기
QgsApplication.processingRegistry().algorithms() : 사용 가능한 알고리즘 전체 객체 리스트
alg.provider().name() : 알고리즘 provider 이름
alg.name() : 알고리즘 이름
alg.displayName() : 알고리즘 표시 이름
from qgis import processing
for alg in QgsApplication.processingRegistry().algorithms():
print("{}:{} --> {}".format(alg.provider().name(), alg.name(), alg.displayName()))
GDAL:aspect --> 경사 방향
GDAL:assignprojection --> 투영체 적용
GDAL:buffervectors --> 벡터 버퍼
GDAL:buildvirtualraster --> 가상 래스터 생성
GDAL:buildvirtualvector --> 가상 벡터 생성
GDAL:cliprasterbyextent --> 범위로 래스터 자르기
...
알고리즘 이름으로 찾기
[x.id() for x in QgsApplication.processingRegistry().algorithms() if "buffer" in x.id()]
버퍼 (native:buffer)
이 알고리즘은 고정 또는 동적 거리를 사용해서 입력 레이어의 모든 객체에 대해 버퍼 영역을 계산합니다.
둥근 오프셋을 생성하는 경우 선분 파라미터가 사분원을 비슷하게그리는 데 사용할 라인 선분의 개수를 제어합니다.
선끝(end cap) 스타일 파라미터는 버퍼 내부에서 라인 끝부분을 어떻게 처리할지 제어합니다.
결합 스타일 파라미터는 오프셋이 라인의 모서리에 적용될 경우 결합 부위를 둥글게(round) 할지, 마이터(miter)로 할지, 비스듬하게(bevel) 할지 지정합니다.
마이터 제한 파라미터는 마이터 결합 스타일에만 적용할 수 있으며, 마이터 결합 부위를 생성하는 경우 사용할 오프셋 곡선으로부터의 최대 거리를 제어합니다.
----------------
Input parameters
----------------
INPUT: 입력 레이어
Parameter type: QgsProcessingParameterFeatureSource
Accepted data types:
- str: 레이어 ID
- str: 레이어 이름
- str: 레이어 원본
- QgsProcessingFeatureSourceDefinition
- QgsProperty
- QgsVectorLayer
DISTANCE: 거리
Parameter type: QgsProcessingParameterDistance
Accepted data types:
- int
- float
- QgsProperty
SEGMENTS: 선분
반올림한 오프셋을 생성하는 경우, 선분 파라미터가 사분원을 근사치로 계산하기 위해 사용할 라인 선분의 개수를 제어합니다.
Parameter type: QgsProcessingParameterNumber
Accepted data types:
- int
- float
- QgsProperty
END_CAP_STYLE: 선끝 스타일
Parameter type: QgsProcessingParameterEnum
Available values:
- 0: 둥글게
- 1: 평평하게
- 2: 정사각형
Accepted data types:
- int
- str: int를 표현하는 문자열, 예. '1'
- QgsProperty
JOIN_STYLE: 이음새 스타일
Parameter type: QgsProcessingParameterEnum
Available values:
- 0: 둥글게
- 1: 마이터(miter)
- 2: 비스듬하게(bevel)
Accepted data types:
- int
- str: int를 표현하는 문자열, 예. '1'
- QgsProperty
MITER_LIMIT: 마이터 제한
Parameter type: QgsProcessingParameterNumber
Accepted data types:
- int
- float
- QgsProperty
DISSOLVE: 결과물 디졸브
Parameter type: QgsProcessingParameterBoolean
Accepted data types:
- bool
- int
- str
- QgsProperty
OUTPUT: 산출물
Parameter type: QgsProcessingParameterFeatureSink
Accepted data types:
- str: 대상 벡터 파일, 예. 'd:/test.shp'
- str: 임시 메모리 레이어에 결과를 저장하는 'memory :'
- str: 벡터 공급자 ID 접두사 및 대상 URI 사용, 예. PostGIS 테이블에 결과를 저장하는 'postgres:…'
- QgsProcessingOutputLayerDefinition
- QgsProperty
----------------
Outputs
----------------
OUTPUT: <QgsProcessingOutputVectorLayer>
산출물
알고리즘 사용하기(buffer)
result = processing.run("native:buffer",{'INPUT':'mNode','DISTANCE':10,'SEGMENTS':5, 'END_CAP_STYLE':0,'JOIN_STYLE':0,'MITER_LIMIT':2, 'DISSOLVE':False,'OUTPUT':'memory:'})
QgsProject.instance().addMapLayer(result['OUTPUT'])
-- ㄱ) 인라인 뷰
SELECT *
FROM PRODUCT A,
( SELECT AVG(PRICE) AS AVG_PRICE FROM PRODUCT ) B
WHERE A.PRICE > B.AVG_PRICE;
-- ㄴ) 스칼라 서브 쿼리
SELECT *, ( SELECT AVG(PRICE) FROM PRODUCT) AS AVG_PRICE
FROM PRODUCT A
WHERE A.PRICE > A.AVG_PRICE
-- ㄷ) 중첩 서브 쿼리
SELECT *
FROM PRODUCT
WHERE PRICE > (SELECT AVG(RENTAL_RATE) FROM PRODUCT)
3. 서브 쿼리 연산자
서브 쿼리 결과가 1건 이상일 때 사용하는 연산자
종류
이름
내용
ANY
서브 쿼리 결과 중 하나라도 만족하면 조건 성립
ALL
서브 쿼리 결과의 모든 값이 만족해야 조건 성립
IN
서브 쿼리 결과에 포함되는지 확인
EXISTS
서브 쿼리 결과에 특정 집합이 존재하는지 확인
3.1 ANY 연산자
서브 쿼리 결과 중 하나라도 만족하면 조건 성립
예제 1)
영화 분류별 최대 상영시간 집합 추출
상영시간이 상기 집합 중 하나라도 크거나 같은 영화 출력
SELECT TITLE, LENGTH FROM FILM
WHERE LENGTH >= ANY
( SELECT DISTINCT MAX(LENGTH)
FROM FILM A INNER JOIN FILM_CATEGORY B
ON A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
)
-- 서브 쿼리 결과 집합은
-- 178, 181, 183, 184, 185 이다.
-- LENGTH가 상기 집합 중 하나의 값 만이라도 크거나 같으면 참
-- 180의 경우 178보다 크므로 참
-- 170의 경우 아무 데이터도 크지 않으므로 거짓
예제 2)
영화 분류별 최대 상영시간 집합 추출
상영시간이 상기 집합 중 하나라도 같은 영화 출력
= ANY의 경우 IN과 같다.
SELECT TITLE, LENGTH FROM FILM
WHERE LENGTH = ANY
( SELECT DISTINCT MAX(LENGTH)
FROM FILM A INNER JOIN FILM_CATEGORY B
ON A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
)
-- 서브 쿼리 결과 집합은
-- 178, 181, 183, 184, 185 이다.
-- LENGTH가 상기 집합 중 하나의 값 만이라도 같으면 참
-- 178의 경우 178과 동일하므로 참
-- 179의 경우 같은 데이터가 없으므로 거짓
3.2 ALL 연산자
서브 쿼리 결과의 모든 값이 만족해야 조건 성립
예제 1)
영화 분류별 최대 상영시간 집합 추출
상영시간이 상기 집합의 모든 데이터 보다 크거나 같은 영화 출력
SELECT TITLE, LENGTH FROM FILM
WHERE LENGTH >= ALL
( SELECT DISTINCT MAX(LENGTH)
FROM FILM A INNER JOIN FILM_CATEGORY B
ON A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
)
-- 서브 쿼리 결과 집합은
-- 178, 181, 183, 184, 185 이다.
-- LENGTH가 상기 집합의 모든 데이터보다 크거나 같으면 참
-- 185의 경우 모든 데이터 보다 크거나 같으므로 참
-- 180의 경우 178보다 크지만 181보다 작으므로 거짓
3.3 EXISTS 연산자
서브 쿼리 결과에 특정 집합이 존재하는지 확인
동작 중 조건에 만족하는 데이터 발견 시 동작을 멈추므로 속도 빠름
예제 1)
고객중에서 11불을 초과한 지불내역이 있는 고객 추출
SELECT FIRST_NAME, LAST_NAME
FROM CUSTOMER C
WHERE EXISTS (
SELECT 1
FROM PAYMENT P
WHERE P.CUSTOMER_ID = C.CUSTOMER_ID
AND P.AMOUNT > 11
)
ORDER BY FIRST_NAME, LAST_NAME;
import json
from shapely.geometry import mapping, shape
jData = json.loads('{"type":"Polygon","coordinates":[[[1,1],[1,3],[3,3]]]}')
p = shape(jData)
p